Single-Line Machine Learning
Single-Line Machine Learning
Lately I’ve been working on training ML models to generate single-line drawings in my style. I’ve open-sourced the code for my models and the code I used to prepare the dataset.
I’ve started writing deep dives for each phase of the project.
This page includes a broader overview of the story as a whole, linking to the individual sections for more detail.
Why This Project
In part 0 I share how I got started making single-line drawings, and why I found them interesting enough to make them as a daily practice.
In part 1 - Discovering SketchRNN I cover how SketchRNN captured my imagination and why I decided to try training it on my own data. For example, I imagined turning the “variability” up, and generating new drawings based on my old ones?

I hit my first roadbloack when I reached out to the authors of SketchRNN. They estimated that I’d need thousands of examples in order to train a model, but I only had a few hundred at the time.
I decided to keep making drawings in my sketchbooks, numbering the pages, and scanning them to store with a standardized file naming scheme.
In the back of my mind, I held on to the idea that one day I’d have enough drawings to train a model on them.
Several years went by. More sketchbooks accumulated. Eventually, I ran a file count and saw a few thousand distinct drawings.




Preparing the Dataset
I was finally ready to get started. I was going to need:
- a thousand JPEGs of my drawings (at least)
- a stroke-3 conversion process for my JPEG scans
- a SketchRNN model and trainer
- the patience to experiment with hyperparameters
I started by collecting my sketchbook page JPEGs into usable training data.




In part 2 - Embedding Filtering, I cover how I’m using embeddings to filter my dataset of drawings. I used embeddings to solve the problem of filtering everything out of my sketchbook data that wasn’t a single-line drawing - particularly my watercolors.
I also made an exploratory browser to visualize the embedding space of the drawings, and published it at projector.andrewlook.com. Here’s a demo video:
In part 3 - Dataset Vectorization, I cover how I’m vectorizing the scans to prepare them for RNN/transformer training. At this stage in the process, my drawings were converted to centerline-traced vector paths, but they were represented as a series of separate strokes. It’s visible in Figure 3 how the strokes are out of order, since strokes don’t start where the previous stroke left off.
SketchRNN Experiments
Part 4 covers how the dataset I used to train my first model contained drawings with too many short strokes, as in Figure 3. Models trained on this dataset produced frenetic drawings such as Figure 4 (a). I experimented with some RNN training improvements and after filtering short strokes out of my first datasets and training a new model I saw a big improvment, as in Figure 4 (b).


Part 5 covers improvements I made to my preprocessing of the dataset by joining SVG paths up into continuous lines so that the model could learn from longer sequences.



The generated results at this stage were uncanny, but showed a big improvement from the initial results. There were at least some recognizable faces and bodies, as seen in Figure 6.



Also in Part 5, I a preprocessing step to decompose strokes into seperate drawings if their bounding boxes didn’t overlap sufficiently. The size of the dataset roughly doubled, since sketchbook pages containing multiple drawings were broken out into separate training examples as in Figure 7.




v2-splicedata. The rightmost three drawings are distinct rows in dataset 20231214.
Part 6 covers how I filtered drawings by visual similarity. Though I did an earlier pass on visual similarity to filter watercolors out from my single-line drawings, this time I wanted to explore the embedding space of the individual drawings after bounding-box separation had been applied. I found that clustering the drawing embeddings identified clusters I wanted to exlcude from the training data like Figure 8 (a) and Figure 8 (b), and helped me identify clusters that I wanted to include in the training data like Figure 8 (c).



The drawings generated by models trained on this visually-filtered dataset started to look recognizable as containing distinct people or faces, as in Figure 9. Still odd and convoluted, but interesting enough to give me new ideas for drawings or paintings.



Part 7 covers experiments I tried using data augmentation, using tricks to take my existing set of drawings and create a more diverse set of training data. For regular computer vision algorithms looking at images in terms of pixels, it’s common to randomly crop the images, flip them horizontally, and change the colors. For vector drawings like I’m working with, there are a different set of techniques available.



Interpreting the Results
It has also been fun to connect the model’s generation function to an animation builder, so I can watch the machine “draw” in real time. Compared with viewing a static output, the animations reminds me that part of what I love about single-line drawings is the surprise as a viewer.
The drawing might start off nonsensical, and then end up with something recognizable enough to be an abstract figure drawing. Even when I’m drawing, I don’t always know where the drawing is going to end up.
I’m adjusting as my hand moves, and adapting to any unexpected moves or mistakes to try and arrive at a drawing that I like. This is not so different from how SketchRNN generates drawings. One way to look at it is that I’m sampling from a probability distribution of possible next moves, and my decision is made by the muscle memory of what’s happened so far.
Looking at some of the results generated from my SketchRNN models such as Figure 9, they remind me of an experiment I’ve tried in drawing with my eyes closed.
I was curious about how much I’m adjusting drawings based on what I see while I’m drawing. I wanted to see how much of my drawings come exclusively from the muscle memory I’ve developed in drawing faces.
Drawing with eyes closed is a great analogy for how SketchRNN draws. The model is only receiving information about the path has traveled so far. No visual information is available about what the final drawing looks like in pixel space as a real image.



Errors like the ones in my eyes-closed drawings made me think about a common issue with models like SketchRNN that rely on recurrent neural networks.
The problem of “long-term dependencies” refers to the poor performance RNN’s exhibit in understand things that are too far apart in a sequence.
In the case of a drawing, long term dependencies would be things that are far apart in terms of the path the pen takes.
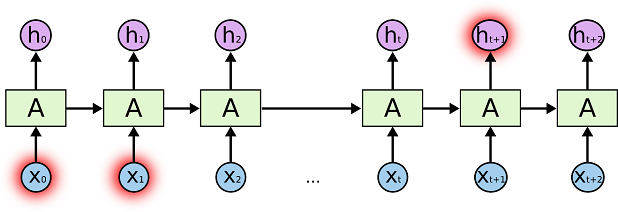
The long-term dependency problem makes intuitive sense to me when I consider my eyes-closed drawings.
Apparently I have muscle memory when I draw eyes and a note in close proximity, and in drawings lips and a chin, but without looking it’s hard to swoop down from eyes to lips and have them be aligned to the nose I drew earlier.

This got me interested in how Transformer models use attention mechanisms to let each step in the sequence take into account the entire sequence at once.
![]()
I came across a paper called Sketchformer: Transformer-based Representation for Sketched Structure, which made a transformer model based on SketchRNN. I decided to try adapting that model for my dataset, and seeing how it compares on handling long-term dependencies.

In my next section on “Training Sketchformer” (coming soon), I cover my experiments using a transformer model instead of an RNN, to see if the model can better handle long-term dependencies within the drawings.